Analyzing financial transactions data of a large number of portfolios and hundreds of millions of transactions and quotes is a demanding job for any computing environment.
Analysis systems don’t necessarily have extremely low latency requirements such as trading systems do, but have to provide low user response times. Applying massive parallelism over CPU cores or even clusters of machines doesn’t help much if you want to achieve response times of a few milliseconds.
Unleashing the extreme power of today’s CPUs with a stream oriented architecture – which is optimal for utilizing caches and branch prediction of modern CPUs – becomes the corner stone in such systems.
This talk will present insights into a system that is based on the idea of multi version concurrency control (MVCC) using Apache Kafka and binary in-memory data representation. Learn how to achieve speed improvements of a factor of 100-200 times compared to classic object oriented design.
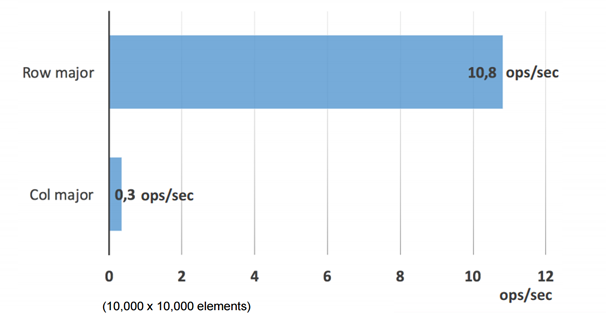
In the opening of his talk “Financial Portfolio Management with Java on Steroids”, Marcus Gründler is asking the following question: When summing up each of the values in a matrix, which is a quite easy problem, which is a faster way to go? One can iterate through the matrix in a row-like matrix, going down row by row to sum it up or an alternative would be going column by column – does it matter? Is one strategy better than the other?
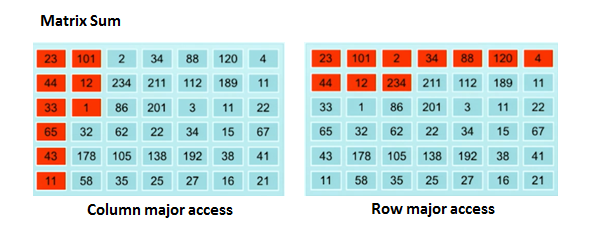
The very surprising results show that the differences between the two are a factor of more than 30 (Depends on the way data is laid in your memory):